서론
페이스북에 리뷰왕 김리뷰라는 페이지가 있다. 갖가지 리뷰들이 올라오고 요새 올라오는 카드뉴스식의 리뷰를 선도한(…?) 페이지이다. 그 김리뷰가 리뷰리퍼블릭이라는 서비스를 만들었다. 사용자들이 리뷰를 작성해서 올리고 양질의 리뷰를 올릴수록 그 보상이 작성자에게 돌아가게끔 하겠다는 취지로 만들었다고 한다. 어쨋든 겉으로 보이는 형태는 조그만한 커뮤니티 앱이다. 어떻게 보면 sns같기도 하고. 어쨋든 그런 조그마한 커뮤니티 앱이 월 100만원 가량의 유지비가 나온다는 소식을 들었다. 서비스 유지비용이 월 100만원씩 나온다면 도저히 수지타산이 안나온다. 곧 망할 것 같았다.
곧 망했다. 그래도 서비스는 사비로 유지되고 있었다. 그래서 비용을 줄이는 데에 도움이 되고 싶었다. 마침 클라우드 서비스를 공부하고 있기도 했고 공부하다가 실질적인 서비스를 운용해봐야 좀 더 실질적인 공부가 될 것 같기도 해서 덜컥 김리뷰계정에 메세지를 보냈다. “아무리 봐도 100만원은 오바다. 회사가 망하기도 했고 여러가지로 힘든상황인것 같지만 리뷰리퍼블릭의 취지 자체는 좋은것 같다. 나에게도 한 사이트의 비용구조 개선은 공부가 된다. 도와주겠다.” 라고 연락을 했다. 그러나 첫번째에는 답이 없었다. 다시 연락했고, 답이 왔다. 만나서 자세히 얘기해보기로 했다.
만나서 계정정보들을 받고 살펴보니 왜 100만원이라는 돈이 나오는지는 알 것 같았다. 일단 이미지 서버비용(imgix)이 너무 많이 들고, 안쓰는 리소스들이 너무 많았다. 개발서버, 스테이징 서버들을 클라우드에 올려놓았지만… 개발자가 없는걸? 놀고 있는 서버들이 많았다. 일단 놀고있는 서버들만 정리하면 비용은 좀 줄일 수 있을 것 같았다. 그래서 흔쾌히 작업을 수락했고 금방 끝낼 수 있을것 같았다.
착각이었다. 생각보다 복잡한 구조를 가진 어플리케이션이었고 많이 쓰이지 않는 프레임워크(meteor.js)로 제작되어있었다. 해당 프레임워크를 공부해야했고, 리소스들은 정리가 안되어 있었다. 오버스펙으로 인프라가 구성된 이유가 있었다. 어플리케이션 자체가 비효율적으로 제작되어 있었다. 그러니깐 애초의 생각처럼 인프라 구성만 바꾼다고 되는게 아니라 어플리케이션 자체를 수정해야 비용구조를 개선하고 퍼포먼스도 올릴 수 있는 프로젝트였던 것이다. 결국엔 소스코드까지 뒤져봐야했다.
누구나 처음엔 그럴듯한 계획을 갖고있다.
일단 인프라부터 옮기자
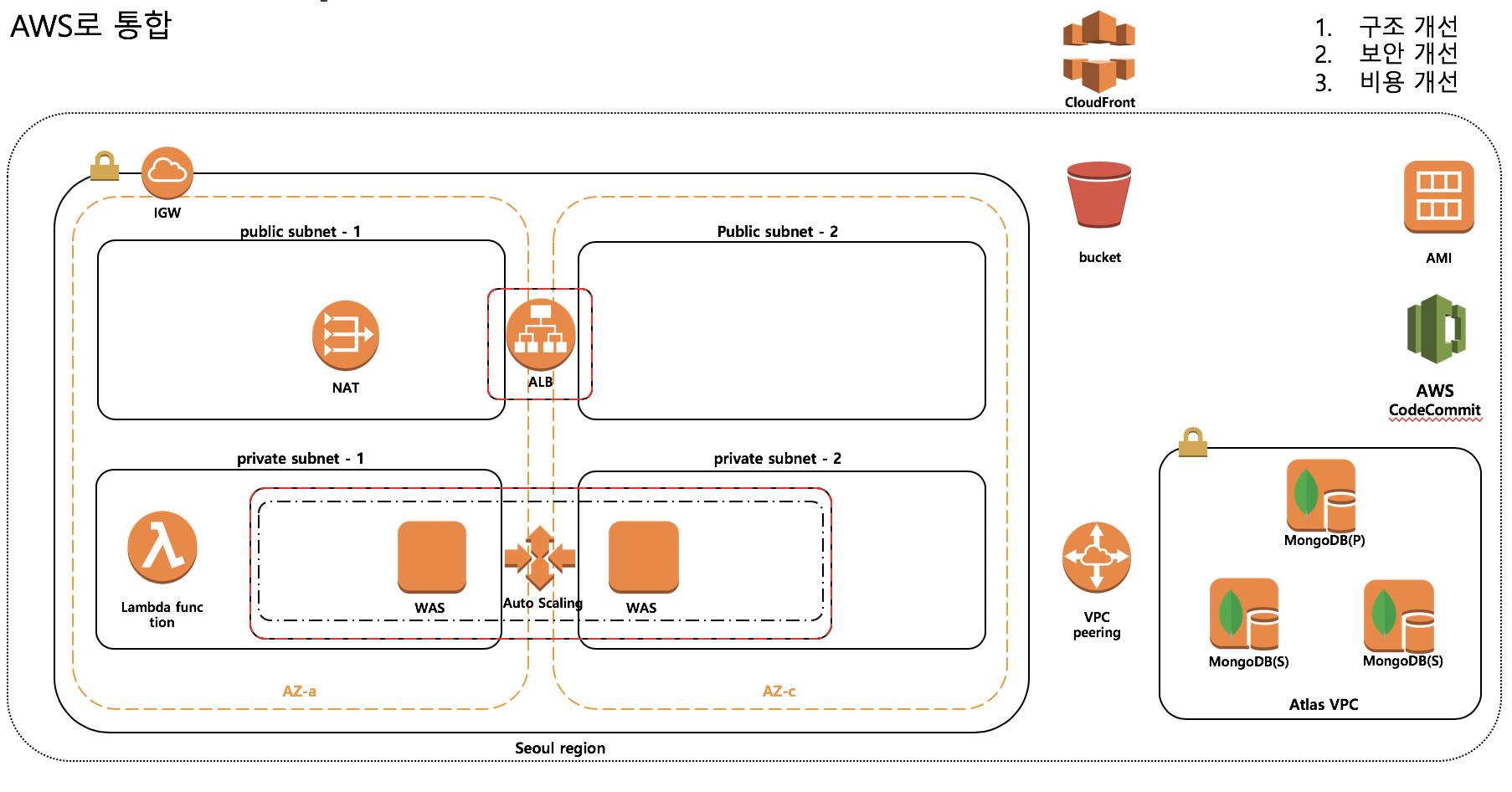
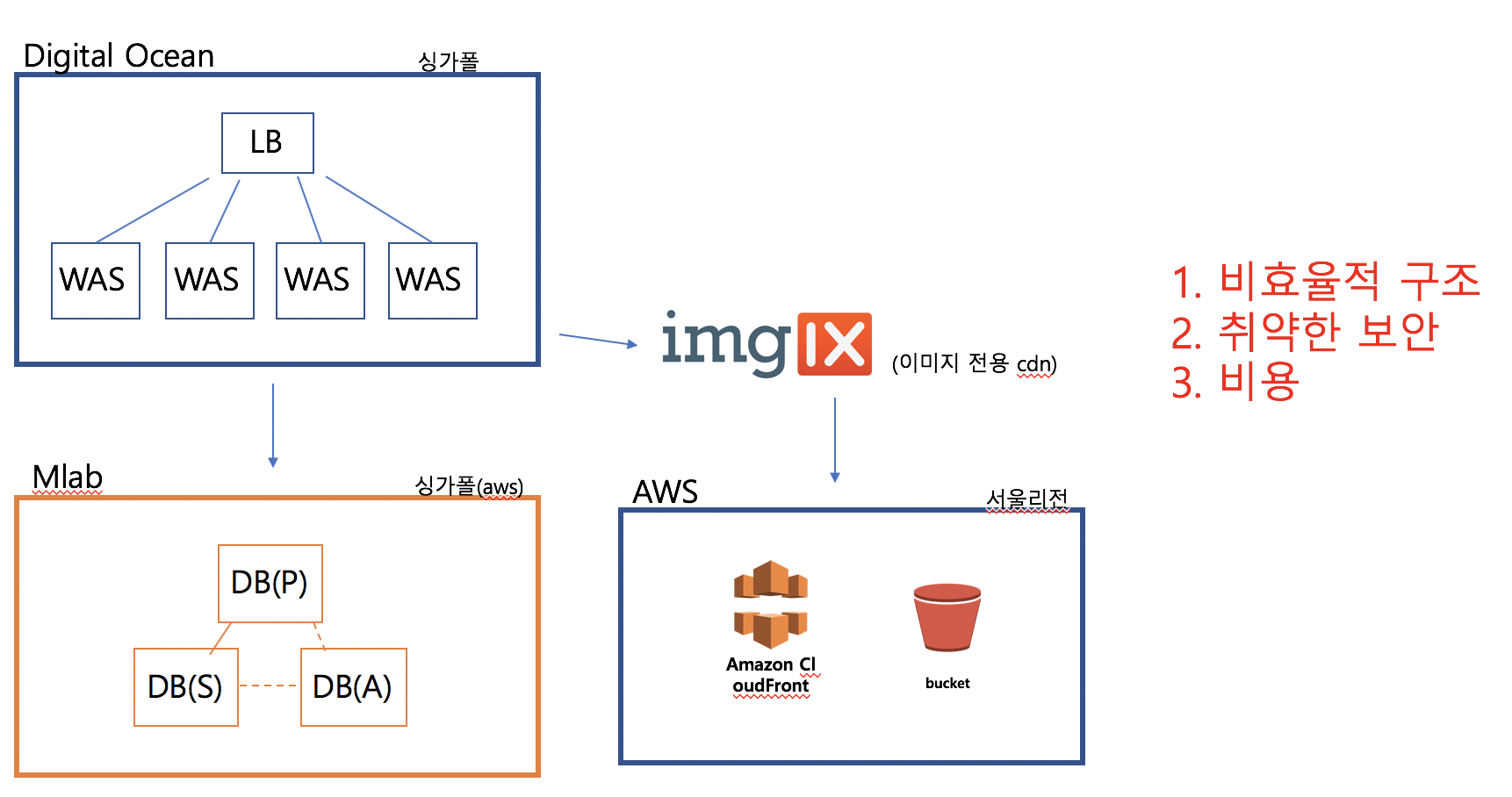
그래도 하는 수 없이 일단 인프라 레벨에서부터 접근했다. 메인 어플리케이션이 돌고 있는 서버는 digital ocean이라는 클라우드 서비스를 통해서 운영되고 있었다. 디지털오션의 서비스 자체에는 큰 문제가 없었다. 어차피 복잡한 구조의 어플리케이션이 아니라 단순한 웹어플리케이션이기 때문에 어떤 서버를 이용하든지 큰 상관은 없다. 다만 문제는 서비스 규모에 비해서 지나치게 많은 리소스들이 사용되고 있었다. 아래 그림에서 보이겠지만 실제 서비스에 이용되는것은 로드밸런서 노릇을 하는 서버 한대와 그 밑에 웹서버가 동작하고있는 서버 4대, 즉 5대가 전부였지만, 배치서버, 검색서버, 스테이징 서버, 젠킨스 서버, 개발 서버 등 합쳐서 16개의 서버가 돌아가고 있었다. 돈이 많다면야 이렇게 해놓는게 관리나 개발차원에서 편하겠지만 이미 망해버린 상황에서는 많이 오바였다. 그래서 하나하나 서버들, 서버위에 올라간 코드들을 훑어보면서 실제 서비스와 연관이 없는 서버들은 일단 모두 정지시켰다.
또 다른 문제점은 DB 서버였다. 리뷰리퍼블릭은 몽고DB를 사용하고 있는데 Mlab에서 제공하는 SaaS 형태의 서비스를 이용하고 있었다. 일단은 이 서비스가 매우 창렬하다는게 문제였다. 한달에 $180나 되는 비용을 지불하는데 거기에 돌아가는 인스턴스는 매우 낮은 스펙이었다. 또한 이 서비스를 이용하면 DB서버는 AWS 위에 올라가게 되는데 그렇게 되면 Digital Ocean <-> AWS 간의 구간에서 퍼블릭 인터넷망을 이용해야 했다. 보안상으로도, 네트워크적인 측면에서도 마이너스이다.
결국 DB서버도 마이그레이션을 해야했고 그러던 와중 mongodb에서 직접 운영하는 SaaS형태의 서비스인 Atlas를 검토하게 되었다. 제공하는 기능도 Atlas가 더 많았고 결정적으로 같은 가격에 제공되는 인스턴스의 스펙이 Atlas가 훨씬 좋았다. 게다가 $100 무료쿠폰도 얻었다. 사실 MongoDB를 그냥 AWS 서버 위에 올려서 운영하는 것도 검토해봤지만 Atlas에서 제공하는 on-line 마이그레이션, 성능 모니터링, 자동 fail-over 등의 기능이 마음에 들었다. 내가 직접 관리하게 되면 저런것들을 다 수동으로 작업해야되는데 기본으로 제공해주니 엄청난 메리트였다.
DB 서버를 마이그레이션 하기로 결정을 하고 나니 다시 어플리케이션서버가 Digital Ocean에 올라가있는 게 걸렸다. 사실 애초에 AWS로 옮길 생각이었다. 내가 편한 환경이기도 하고 Digital Ocean이 서울에 서버가 없기도 하고, 여타 기능에선 AWS가 압도적이기 때문. 또한 DB가 AWS에 올라가기 때문에 어플리케이션 서버도 AWS에 올라가있는 게 성능면에서나 안정성면에서나 훨씬 낫다. DB 서버가 위치하는 네트워크(VPC)와 어플리케이션 서버가 위치하는 네트워크 사이에 VPC Peering을 맺으면 AWS의 내부망을 이용할 수 있다.
그래서 일단 기본적인 마이그레이션의 가닥은 다음과 같았다.
- 어플리케이션: Digital Ocean -> AWS
- DB: Mlab -> Atlas
이러면 일단 인프라적으로는 비효율적인 부분을 많이 개선하는 것이라고 생각했다. (그럴리가…)
다음 포스팅에서는 Digital Ocean -> AWS 로 옮기는 작업때 있었던 일들에 대해서 다뤄보겠다.
리뷰리퍼블릭의 기존 아키텍쳐
리뷰리퍼블릭 변경 아키텍쳐