Athena, 심플하고 강력하지만 아쉬운 인터페이스
이번 포스팅에서는 Athena 와 Zeppelin을 엮어서 사용하는 방법에 대해서 정리하려고 합니다. Athena는 써보면 써볼수록 요물이라는 생각이 드는 제품입니다. S3에 데이터만 잘 저장해 놓으면 그걸 SQL문으로 빠르게 쿼리할 수 있다는 컨셉이 간단하지만 강력하네요. 다른 분산처리 플랫폼도 많지만, 일단 간단하게 시작하기에는 Athena가 최적인것 같아요.
다만, Athena가 워낙 심플한 구조를 갖고 있고 제공해주는 기능도 심플하다 보니 조금 아쉬운점도 있는데요, 일단 제 생각에 가장 아쉬운 점은 인터페이스 입니다. ‘대화형 쿼리’ 라는 컨셉으로 단순한 쿼리창만 갖고 있지만, 사실 ‘대화형’ 이라는 말처럼 채팅기록이 남진 않는게 제 생각엔 커다란 단점인 것 같아요. 우리나라 정서가 워낙 UI에 이것저것 많은 기능을 좋아해서 상대적으로 AWS의 UI가 좀 빈약하다는 느낌을 많이 받는데 Athena의 인터페이스도 그 중 하나인 것 같습니다. 그래도 ‘대화형’이라는 컨셉을 완성하기 위해서는 조금 더 인터페이스가 발전해야 할 것 같다고 생각합니다.
예를들어, 웹로그를 분석하는 과정에서 이전 쿼리의 결과를 들고 있어야 하는 경우가 있습니다. 다음과 같이 요청수 top 10의 정보를 받아왔다고 합시다.
-- 요청수 top 10 client ip
select client_ip, count(*) as requests from "logs"."alb_logs_apache"
group by client_ip
order by requests desc
limit 10;그리고 이제, 여기에 나온 client ip 각각에 대해 다음과 같은 쿼리를 통해 어떤 행동을 하는지 알아본다고 합시다.
-- top 10 ip 각각에 대해 어떤 행동을 하고 있는지 조사
select * from "logs"."alb_logs_apache"
where client_ip='000.000.000.000'이런 작업을 하려고 하면 athena에서는 쿼리창을 따로 만들어 놔야 합니다. 사실 쿼리 창을 따로 만들어 놓아도 결과가 잘 저장되지 않는 버그(?) 같은게 있습니다.
Zeppelin으로 인터페이스를 보강
이러한 단점을 단번에 해결해주는게 바로 Zeppelin 입니다. Zeppelin은 Jupyter 처럼 노트북 환경을 제공해주는 오픈소스 프로젝트입니다. Zeppelin에 대한 소개는 https://medium.com/apache-zeppelin-stories/%EC%98%A4%ED%94%88%EC%86%8C%EC%8A%A4-%EC%9D%BC%EA%B8%B0-2-apache-zeppelin-%EC%9D%B4%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80-f3a520297938 에 잘 정리되어 있네요. 짧게 설명을 드리면, Zeppelin은 Spark 작업을 편하게 하기 위해서 만들어 놓은 노트북이지만, 써보니 다른 분석 툴과도 같이 쓰이고 Athena 와도 매우 잘 맞는 노트북인 것 같습니다.
Zeppelin 화면 예시
위에서 언급했지만 Athena에서 주창하는 ‘대화형 쿼리’의 컨셉을 결국 완성시키려면 ‘노트북 인터페이스’ 가 있어야 완성이 되는것 같아요. 쿼리문의 특성상, 그때 그때 궁금한 것을 쿼리로 날리려면 이전의 결과를 들고 있어야 하는 경우가 매우 많고, 또한 그 쿼리문의 결과를 시각화해서 볼 수 있으면 사용성이 정말 매우매우 좋아집니다. 만약 제가 아마존의 Product 팀에 있다면 Athena의 웹 인터페이스를 당장 노트북 인터페이스로 바꾸자고 하고 싶을 정도로, 아 아테나의 완성은 이거다. 싶었습니다.
Zeppelin 설치
참고: https://b.luavis.kr/server/zeppelin-with-athena
zeppelin과 athena를 연동하는 방법은 위의 포스팅에 아주 정리가 잘 되어 있습니다.
Zeppelin 에서 ALB 로그 분석
Zeppelin의 설치는 위의 포스팅을 쭉 따라가서 성공하셨을거라고 믿습니다. 그럼 Athena X Zeppelin의 강점을 ALB의 로그를 이리저리 쿼리해 보면서 느껴(?)보도록 합시다.
ALB로그는 기본적으로 Apache 로그 포맷에 ALB에서 제공하는 컬럼이 추가된 형태입니다. (Lambda와의 연동 기능이 추가되면서 로그에 컬럼도 추가되었습니다.) 저는 간단하게 ALB에 apache 서버를 물려서 예제 사이트를 구축해놓았습니다. 트래픽은 굳이 일부러 만들진 않고 제 로컬에서만 몇번 들어가보았더니 많이 나오진 않았습니다. 결국 로그가 많이 나오진 않아서 굳이 Athena를 쓰지 않고 Excel 같은 툴로도 충분히 로그를 이리저리 뜯어 볼 수 있었으나, 일반적으로 ALB로그는 양이 많아서 Excel같은 걸로는 뜯어보기가 굉장히 어렵습니다. (버벅댑니다.) 그래서 Athena X Zeppelin을 통해서 간단하게 쿼리하고, 시각화까지 해보도록 하겠습니다.
기본적으로 ALB는 로그를 활성화하면 S3에 저장되고, Athena는 다음과 같은 DDL을 통해 ALB로그를 바라보는 테이블을 생성할 수 있습니다.
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
new_field string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\"($| \"[^ ]*\")(.*)')
LOCATION 's3://your-alb-logs-directory/AWSLogs/<ACCOUNT-ID>/elasticloadbalancing/<REGION>';파티션을 나눠주면 더 좋겠지만, 지금은 일단 데이터 양이 많지 않으므로 생략합니다. 일단 테이블을 만들었으니, 테이블이 어떻게 생겨먹었는지 확인해 봐야겠죠.
-- 테이블 예시
select * from "logs"."alb_logs_apache"
limit 10;네, ALB의 컬럼들은 이렇게 생겼습니다. 그럼, 제 가짜 사이트에 요청이 몇번이나 들어왔는지 확인해 볼까요?
-- 전체 리퀘스트 수
select count(*) as requests from "logs"."alb_logs_apache";그럼, 어떤 분들이 들어왔는지 확인해보도록 하겠습니다.
-- 요청수 top 10 client ip
select client_ip, count(*) as requests from "logs"."alb_logs_apache"
group by client_ip
order by requests desc
limit 10;음… 제 가짜 사이트에 관심이 많은 이분들은 그럼 어떤 요청들을 날리는지 볼까요?
-- 특정 Client_ip의 요청 URI
SELECT request_url
FROM "logs"."alb_logs_apache"
WHERE client_ip='000.000.000.000'역시, 이상한 bot입니다. 워드프레스의 취약점을 노리는 봇들이 많다고 하는데 실체를 이렇게 확인하게 되네요.
그 외에도 응답을 잘 주고 있는지 봐야겠죠?
-- 응답 코드 별 count
select elb_status_code, count(*) from "logs"."alb_logs_apache"
group by elb_status_code
order by count(*) desc;정상적인 사이트라면 200 응답이 많겠지만, 제 사이트에는 200응답 보다는 404 응답이 많네요. 여기서 진짜 좋은점은, Zeppelin에서 파이차트도 간단하게 만들 수 있다는 점입니다. 한눈에 쏙 들어오니 보기가 좋네요.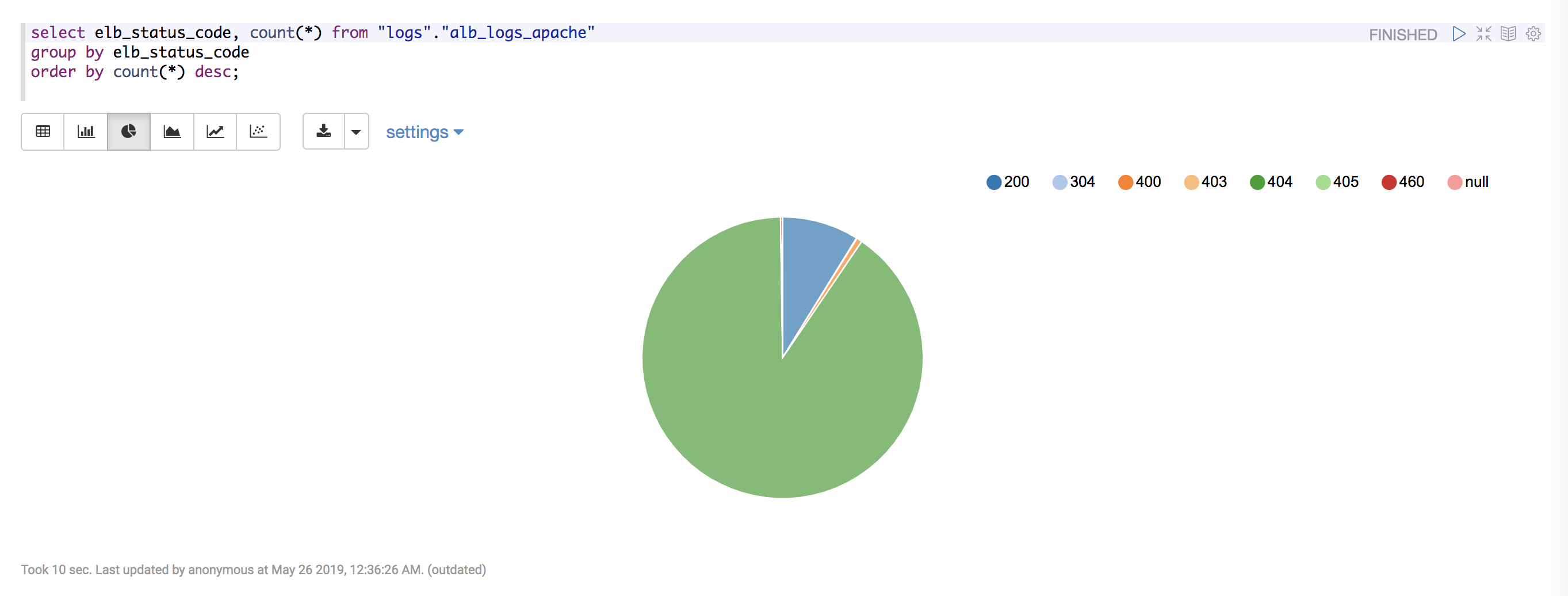
-- target ip 별 count (로드밸런싱이 잘 되고 있는지. )
select target_ip, count(*) from "logs"."alb_logs_apache"
group by target_ip;위처럼 로드밸런싱이 잘 되고 있는지 확인하는것도 간단해 보이지만 중요합니다. 실제로 로드밸런싱이 잘 안되고 있는 사례도 많고, 그런 경우 장애의 포인트가 되기도 때문입니다.
-- 시계열 분석...
select date_trunc('hour',from_iso8601_timestamp(time)) as TIME, count(*) as count
from "logs"."alb_logs_apache"
group by TIME
order by TIME ASC;시계열 분석을 위해서는 위에 코드 처럼 먼저 String 타입으로 된 시간을 Date 타입으로 변경해주는 작업이 필요합니다. 또한 로그상에는 ms 단위까지 표현이 되지만 시간단위로 잘라줘야 집계가 편합니다. 위와 같이 쿼리하면 시간단위로 내 사이트엔 몇명이 오는지 파악할 수 있고, 제플린에서는 line chart로 바로 시각화가 가능합니다.
아래처럼 대시보드를 만들 수 도 있습니다.
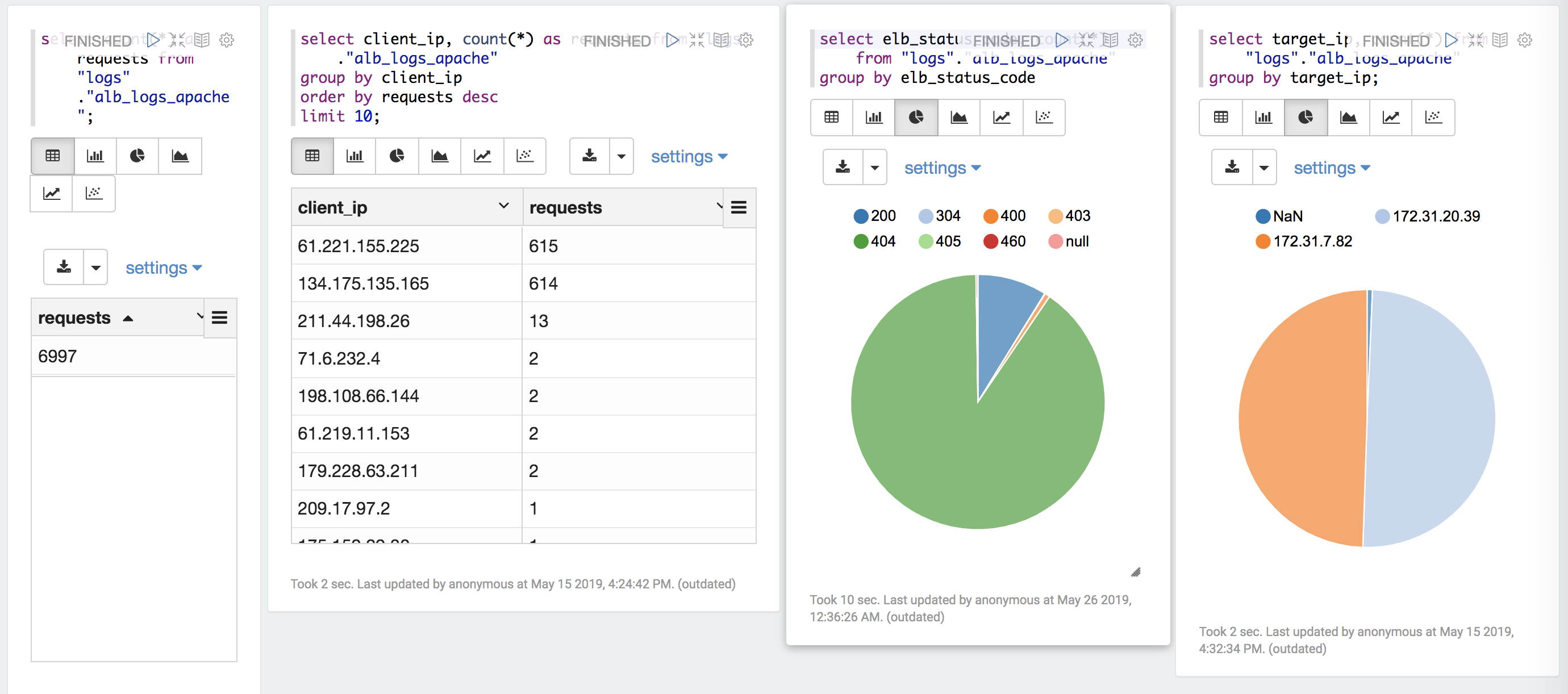
Athena X Zeppelin
위의 예시처럼, Athena의 아쉬운 인터페이스를 Zeppelin을 통해 보완할 수 있습니다. 설치도 docker를 통해서 간단하게 진행할 수 있고, Zeppelin의 공유 기능을 이용하면 팀원 간에 협업도 가능할 것 같고 좋네요. 개인적으로는 Quicksight 처럼 애매한 BI 툴을 쓰는 것보다는 무료인 Zeppelin을 쓰는 것도 전문적인 BI를 요구하는게 아니라면 괜찮을 것 같습니다.