Lambda가 진정한 cloud native인걸까!
300원에 200만뷰 소화하기라는 포스팅을 읽은 적이 있습니다.
그리고
AWS와 함께 천만 사용자 웹서비스 만들기라는 슬라이드도 본 적이 있습니다.
저 슬라이드를 처음 봤던 때에는 Lambda에 대해서 많이 사용을 안해봐서 그런지 저 자료들만 보면 왠지 엄청난 트래픽을 아주 적은 비용으로 큰 문제 없이 수용할 수 있을 것만 같았습니다. 그러면서 언젠가 full-serverless 로 구성된 서비스를 한번 만들어 봐야겠다는 생각을 했었습니다. 생각만요.
생각해보면 단순히 REST API에 대한 요청만 받아주는 서비스라면 API GATEWAY + Lambda 로만 구성하는게 충분히 메리트 있을것 같았습니다. 그러면 정말 진정한 의미에 Pay-as-you-go 를 구현하는 클라우드 네이티브를 구현해볼 수 있지 않을까요…?
Lambda@Edge와의 만남
그러던 중 우연찮게 Lambda@Edge를 사용해야 하는 일이 생겼습니다. 특정 헤더를 추가하거나 제거하는 단순한 로직을 Cloudfront에 추가해야 하는데 Cloudfront 자체로는 그런 기능을 제공하지 않기 때문입니다. 개발자체는 간단했습니다. 그런데 막상 실 트래픽에 적용하려고 하니 Lambda@Edge의 동시성 제한이라는 항목이 눈에 들어왔습니다.
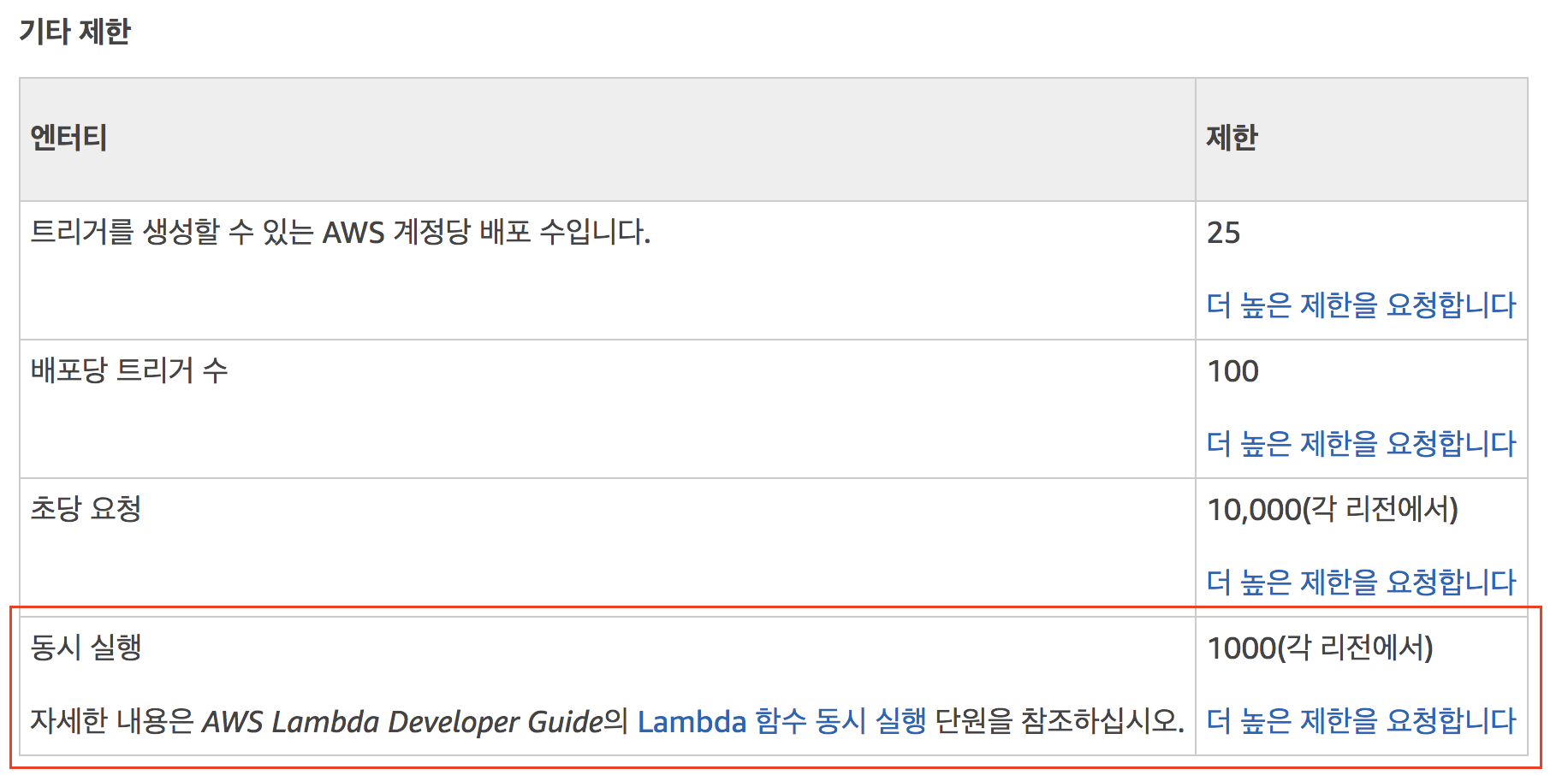
Lambda@Edge는 각 리전에서 1000번의 동시실행 한도를 갖는다고 나와있습니다.
이게 막상 딱 “1000번 동시실행 제한” 이라는 말만 들으면 ‘뭐야 1000밖에 안돼?’ 라는 생각이 듭니다.
그래서 결국 당시에 서비스 오픈 전에 급하게 Limit 증설 요청을 했던 기억이 납니다. 게다가 저 Limit은 증설을 원하는 Region을 정하고 사유를 말해야 합니다. 결국 그때 막 support 엔지니어랑 전화도 하고 그래서 겨우 Limit을 높여놓은 기억이 있습니다.
그때 사실 결국 트래픽이 많이 들어오진 않아서 저 Limit 내에서 처리가 되긴 했습니다. 그런데 그 당시 트래픽을 아주 일부 (약 1%?) 가량만 태운거라서 만약에 전체 트래픽을 부었으면 무조건 장애가 발생하는 상황이 났을겁니다. 1%만 부었는데도 peak로 발생했던 동시성이 한 300정도는 되었으니까 단순히 10배의 트래픽이 온다고 가정해도 limit 1000은 훌쩍 넘어가겠죠.
Limit 1000이 적은걸까 많은걸까?
‘Limit 1000’ 이라는 게 사실 작은 수치는 아닙니다. 왜냐하면 이건 단위가 tps같은게 아니라 말 그대로 ‘동시 실행 수’이기 때문이죠. 굳이 풀어서 설명하자면 ‘어느 한 순간에도 Lambda 함수가 동시에 1000개 이상 실행될 수는 없다’ 는 말입니다. 이걸 다시 풀어서 얘기하면, 좀 말도 안되는 가정이긴 합니다만 약 100ms 이내에 끝나는 로직이 완전 동기적으로 1000개가 동시에 실행되고 끝난다고 한다면 이 함수의 tps?는 단순 계산으론 1만 tps 이상이 됩니다.
그렇지만 이게 Limit이기 때문에 또 엄청 넉넉한 수치는 아닙니다. 특히 CDN은 보통 대량 트래픽을 가정하기 때문에 1초에 1만정도 처리한다고 가정해도 어떻게 보면 턱없이 모자란 수치일 수도 있는거죠. 그래서 저는 Lambda@Edge가 참 애매한 서비스라고 생각을 합니다.
물론 모든 로직을 Origin Response, Origin Request 등으로 몰아서 최대한 캐싱이 되게끔 만들면 대규모 트래픽에도 대응이 가능할 것 같긴한데, 그럴거면 그냥 원본서버 건드리는게 더 빠르지 않을까요?
CDN 자체의 성능을 훼손하지 않으면서 캐시와 사용자 사이의 logic을 컨트롤 할수 있어야 진정한 Lambda@Edge가 가능한 것 같고 그러려면 Viewer 단의 Lambda 동시성이 CDN이 제공하는 대역폭과 동시성 만큼을 커버해 줘야 할텐데 지금 제공하는 1000으로는 엄청 부족하죠. 즉, viewer 단의 Lambda를 적용해서 뭔가 이득을 보기엔 조금 애매해 보입니다.
물론 이 동시성을 늘려주긴 합니다. 그런데 보니깐 이 Limit을 늘려주는 데에도 꽤 많은 시간이 소요되더라구요. ELB Prewarming 처럼 바로바로 되는건 아닌 것 같았어요. (물론 ELB 프리워밍도 미리미리 해두어야 합니다.)
같은 맥락에서 일반적인 서비스의 was 대신에 이 Lambda를 이용하기에도 좀 애매한 수치가 됩니다.
즉, 저는 이 Limit 1000 이라는 수치가 애매한 수치로 보입니다. 트랜잭션이나 비지니스 로직이 복잡하고 많이 일어나는 어플리케이션에서는 이 수치가 매우 부족할수도 있을것 같네요. 그리고 유저 수가 동접 1만 명이 훌쩍 넘는다면 1000으론 어림도 없을 것 같습니다.
그런데 그냥 동접 1만명이 안되는 서비스 라면, 이 Limit 때문에 Lambda 도입을 망설이지는 않았음 좋겠습니다. 오히려 작은 규모의 서비스에 Lambda를 적용했을 때 비용적인 측면에서 효과가 엄청날거라고 생각하거든요.
갑자기 결론?
결국, ‘Lambda가 정말 좋긴한데 이 동시 실행 수 제한이라는 걸 서비스 구축시에 고려해야 한다’는 글이 이렇게 길어 졌네요.
기왕 길어진 김에 사설을 덧붙이자면, 천만 사용자를 가정한 서비스의 모든 백엔드를 Lambda로 구축할 수 는 없을 것 같습니다. 그런데 한 1만? 정도 까지는 충분히 Lambda만으로도 백엔드를 구축할수 있지 않을까 생각해봅니다. S3, API Gateway, Lambda, DynamoDB 만으로 이루어진 1만 사용자 어플리케이션… 한번 만들어 보고 싶네요.
다음 글에선…
이번 글은 사실 ‘Lambda의 동시성을 컨트롤 하는 방법’의 서론을 쓰다가 길어져 버린 글입니다. 다음 글에서는 진짜 Lambda의 동시성을 컨트롤 하는 법에 대해서 한번 써볼 생각입니다.
여담…
좀 이상한 방향으로 글이 흘러갔다는걸 느끼면서도 오늘은 일단 글을 오랜만에 쓴다는 것과 그 글을 마무리하는 데에 가장 큰 목적이 있기에 이렇게 중구난방한 글을 적습니다.
저는 책을 읽을 때 서론 읽는게 제일 재밌던데 쓸 때도 마찬가지로 서론 쓸 때가 제일 재밌는것 같아요. 기슬 블로그를 쓸 때는 유용하려면 막 자료도 들어가야 되고 검증된 코드도 들어가야되고 하잖아요. 근데 오늘 쓴 서론?처럼 약간 전체 글에대한 소개이면서도 그 주제에 대한 저의 정리이기도 한 글이 쓸 때 재밌는 것 같네요.
무슨 코드 한 줄 없이 기술블로그를 쓰나 싶지만서도 오히려 이런 글들이 있는 블로그도 나름 재미있지 않으려나요. 방법이나 실제 practice는 없고 의견만 있는 이런 글이 실질적인 도움이 되지는 않겠지만, ‘아 이 사람은 이런 기술에 대해서 이렇게 생각하는구나’는 걸 보는 것도 필요하지 않을까 싶네요.