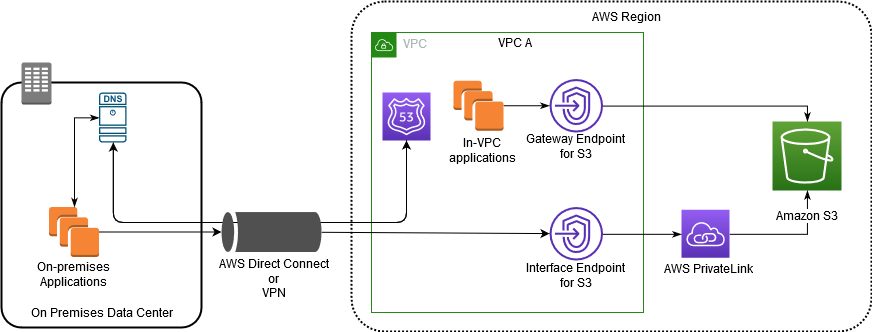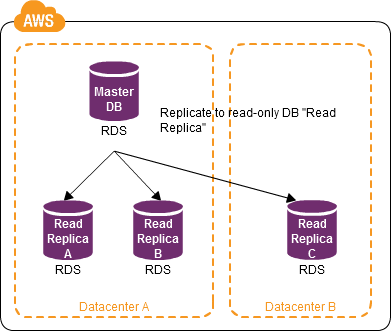

빅데이터를 공부해야할 일이 생겨서, 하둡을 먼저 공부했다. 쌩으로 클러스터를 만들고, 설정값을 변경해보고… 그렇게 클러스터를 만드는 일부터 맵리듀스 어플리케이션을 만드는 일까지 공부하는게 쉽지만은 않았다. 여기서 약간 빅데이터의 벽(?)같은걸 1차로 느꼈다.
그러다가 스파크를 만났다. 공부하다 보니 스파크가 그렇게 어렵지도 않고, 그런데 활용성은 굉장히 좋고, 성능도 좋다는 생각이 든다. 여기서 포인트는 그닥 어렵지 않다는 점이다. 자료들이 주로 scala라는 생소한 언어로 설명이 되어있지만, scala가 별로 어렵지 않다. 언어자체가 직관적이면서 간결하다. 그리고 scala로 배우는 스파크도 그닥 어렵지가 않다. 많은 기능을 제공하고 좋은 성능을 제공하지만, 기능들의 추상화가 잘 되어있어서 단순히 api만 호출하면 된다.
이거 사긴데? 쉽고 빠른 빅데이터 처리 엔진이라니…
그 동안 하둡을 공부하면서 느낀 어떤 답답함 같은게 해소되는 느낌이랄까. 맵리듀스를 짜면서 뭔가 병렬처리로 성능이 향상된다는건 알겠는데 코드 작성이 상당히 번거로웠다.(책에는 간단하다고 나와있는데 원리야 간단하지만 코드짜는건 안간단함 ㅇㅇ) 물론 하둡에는 맵리듀스 외에도 빠르게 분석할 수 있는 엔진들이 있지만, 그 중에 스파크가 가장 매력적으로 보인다.